Similarity Metrics for Categorization: from Monolithic to Category Specific
Ongoing Project
Project Lead(s)
Synopsis
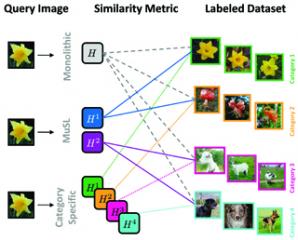
Similarity metrics that are learned from labeled training data can be advantageous in terms of performance and/or efficiency. These learned metrics can then be used in conjunction with a nearest neighbor classifier, or can be plugged in as kernels to an SVM. For the task of categorization two scenarios have thus far been explored. The first is to train a single “monolithic” similarity metric that is then used for all examples. The other is to train a metric for each category in a 1-vs-all manner. While the former approach seems to be at a disadvantage in terms of performance, the latter is not practical for large numbers of categories. In this paper we explore the space in between these two extremes. We present an algorithm that learns a few similarity metrics, while simultaneously grouping categories together and assigning one of these metrics to each group. We present promising results and show how the learned metrics generalize to novel categories.